
あなたが使う言語を選んでください
手頃な価格の
オンプレLLM
トレーニングと
効率的な推論
ソリューション
ソリューションの紹介




あなたにぴったり
予算

使いやすく、導入しやすい

データを安全管理、
プライバシーを守ります
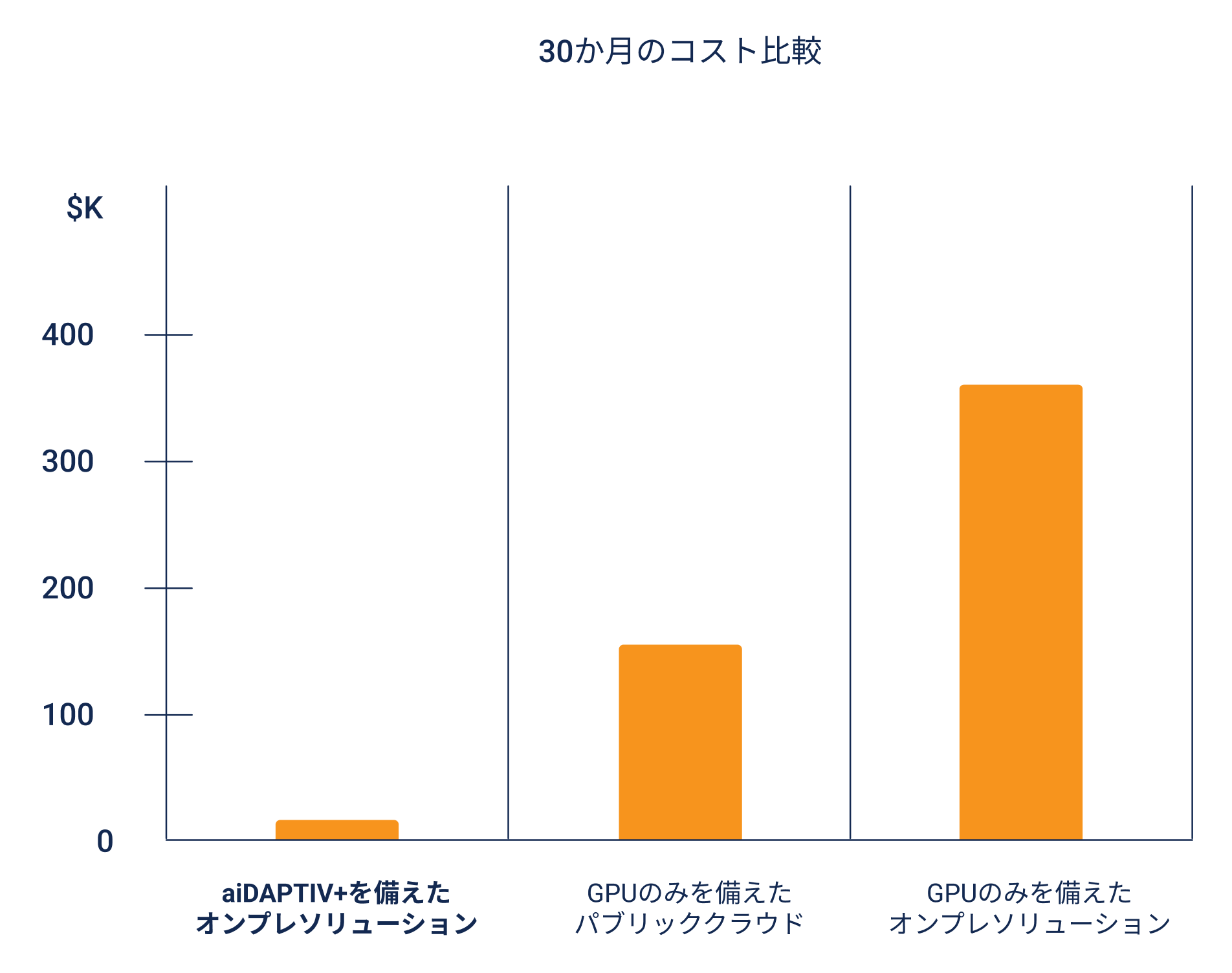
注: オンプレのNVIDIA 6000 ADA GPU 4基と、クラウドのNVIDIA H100 GPU 8基を比較した想定
手頃な価格
高価なHBMやGDDRメモリをコスト効率の良いフラッシュメモリへオフロードして、高コストで電力消費の多いGPUカードを大量に使用する必要性を排除。

使いやすさ
家庭、オフィス、教室、またはデータセンターに簡単に導入可能。省スペース設計で、
一般的な電源と冷却システムで使用可能。
コマンドラインからのアクセス、もしくは直感的なGUIを利用してのアクセスが可能。
モデルの取り込み、ファインチューニング、検証、推論をオールインワンのツールセットで実行可能。

機密性の高いデータ
ファイアウォール内でLLMのトレーニングを実行可能。プライベートデータを完全に管理でき、データコンプライアンスにより、安心で使えます。

AIトレーニングPCでLLM
トレーニングを学ぶ
個人や企業向けに費用対効果の高い AI トレーニングPCを提供することで、単なる推論の学習にとどまらず、モデルのファインチューニング方法も習得可能。これにより、LLMトレーニングの技術人材不足を解消し、独自データを活用したトレーニングを容易に実現。

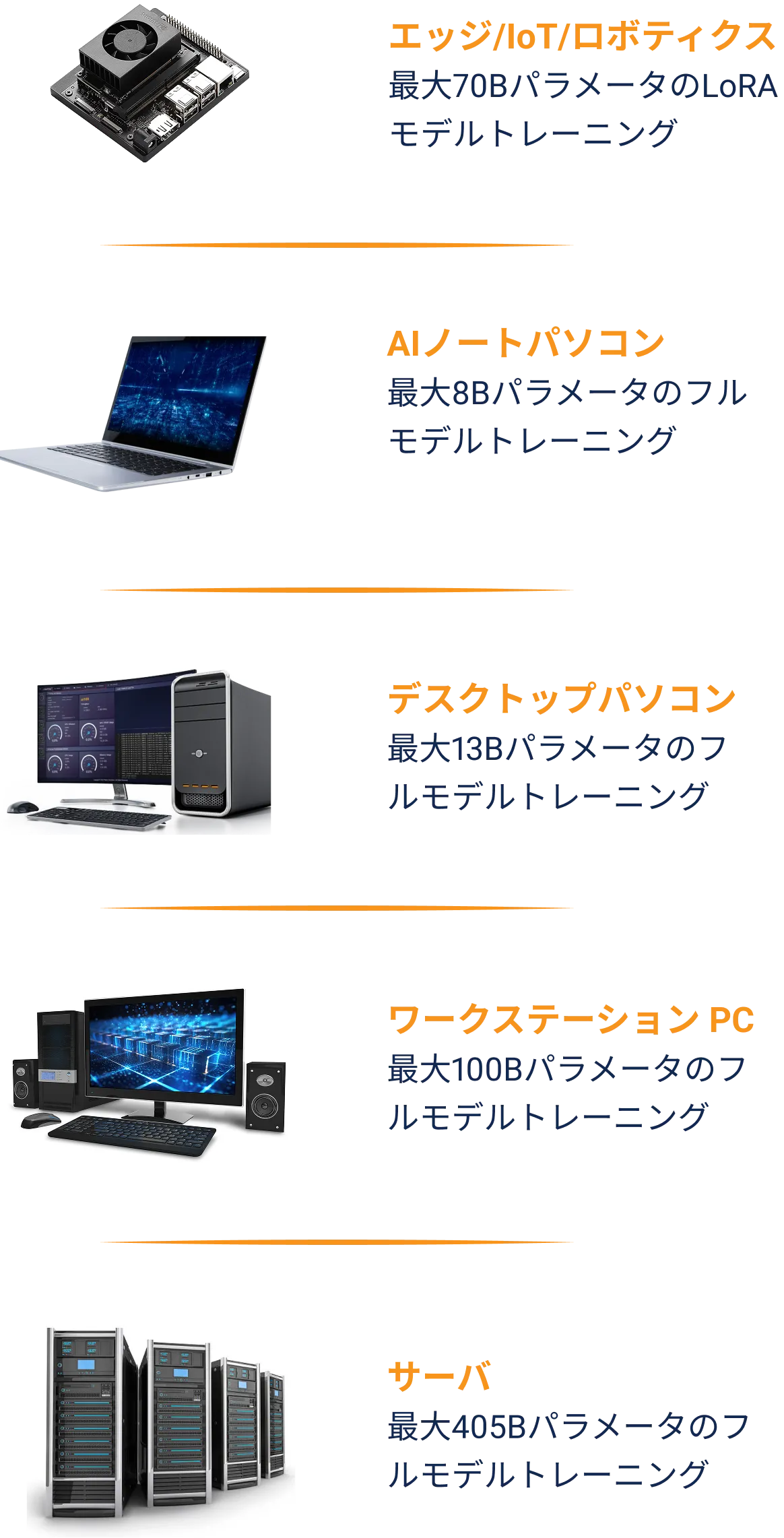
モデルスケールは
無限に拡張可能
追加の人員やインフラストラクチャを必要とせずに、大規模なデータ モデルを簡単にトレーニングできるワンストップ ソリューション。ノードを柔軟に拡張してデータ量を直線的に増加させ、トレーニング時間を短縮します。

エッジコンピューティングと
ロボティクス向けIoT
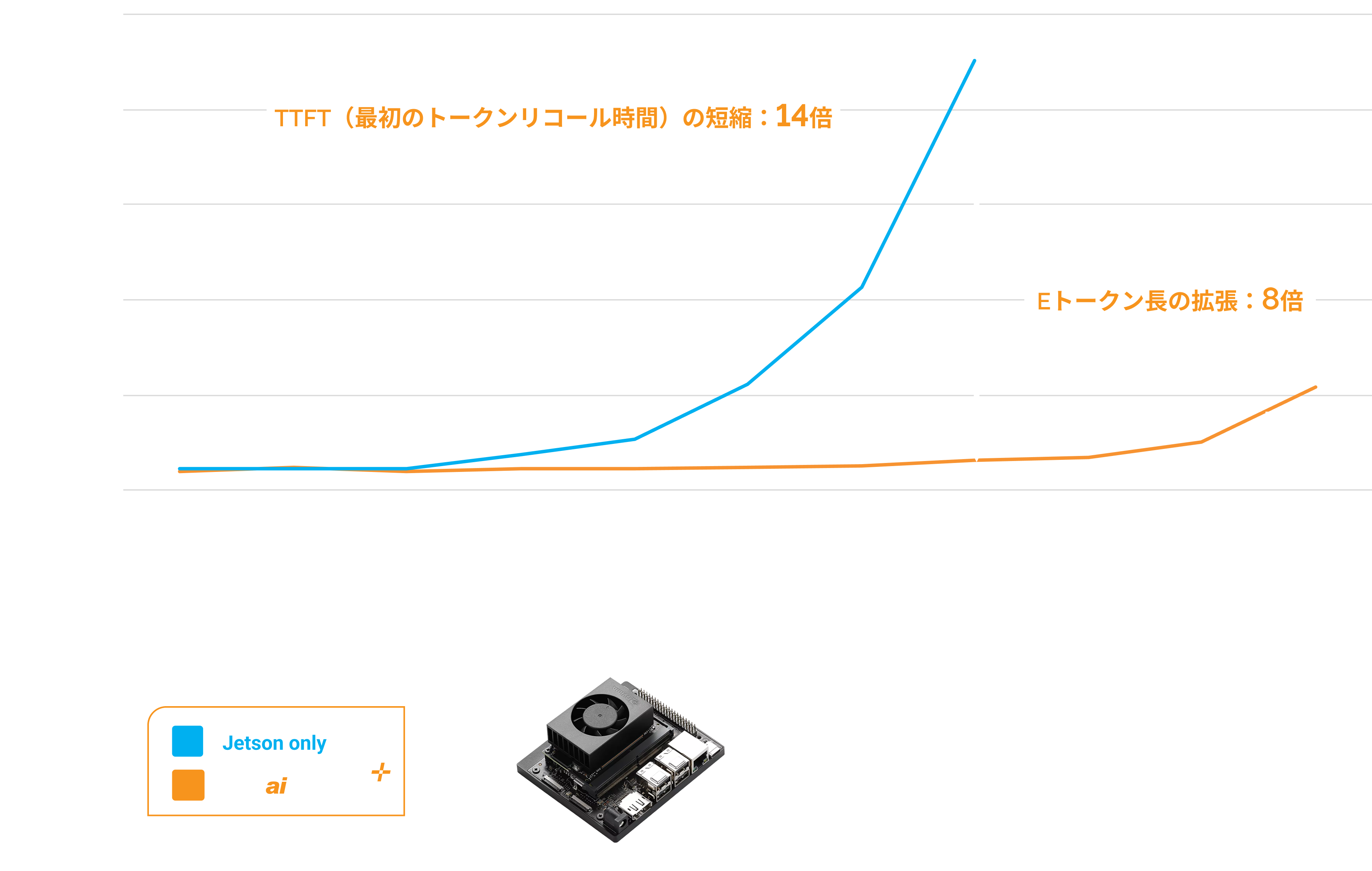
NVIDIA Jetson IoTデバイスは、Phison aiDAPTIV+ を活用して最初のトークンリコール時間を短縮し、推論パフォーマンスを向上させます。さらに、トークン長を拡張することで、より長く正確な回答を可能にします。また、aiDAPTIV+ によりJetson IoTデバイス上でのLLMモデルのトレーニングが可能になります。

AIノートパソコン
GPUとPhison aiDAPTIV+ を搭載したAIノートパソコンを使用することで、個人は自宅やオフィス、教室でLLMのトレーニング方法を学ぶことができます。また、トレーニング済みのLLMをオンプレミスで運用し、自身のデータを活用したモデルにより、推論プロンプトに対するより適切な応答を得ることができます。aiDAPTIV+ を使用すると、プロンプトリコール時間が短縮され、より多くのコンテキストを処理できるため、より長く正確な回答を生成できます。

LLMトレーニングのユースケース
オンプレミスでのLLMトレーニングにより、組織や個人は一般的な知識モデルをドメイン固有のデータで強化できます。これにより、医療診断、財務予測、法的分析、製品開発などの専門分野において、使いやすさ、関連性、精度が向上します。
ファイソンaiDAPTIV+ LLM
トレーニング統合ソリューション
コマンドラインを使用するか、直感的なオールインワンの aiDAPTIV+ Pro Suite を利用して LLM トレーニングを実行します

対応モデル
- Llama, Llama-2, Llama-3, CodeLlama
- Vicuna, Falcon, Whisper, Clip Large
- Metaformer, Resnet, Deit base, Mistral, TAIDE
- さらに多くのモデルを対応する予定です。


内蔵メモリ管理ソリューション
シームレスな PyTorch 互換性を体験し、AI アプリケーションを調整する必要がなく、ノードを簡単に追加できます。システム サプライヤーは、AI100E SSD、ミドルウェア ライブラリの認証とシステムのスムーズな統合を支援する ファイソンの包括的なサポートを利用できます。
メリット
- 簡単に実装
- AI アプリケーションを変更する必要はありません
- 既存のハードウェアを再利用するか、ノードを追加します
aiDAPTIV+ ミドルウェア
- モデルを分割して各GPUに割り当てる
- aiDAPTIV キャッシュ上で保留中のスライスを保持する
- GPU 上で保留中のスライスを完了したスライスと交換する
システム統合
- ai100E SSDを使用可能
- ミドルウェアデータベースライセンス
- ファイソンの総合サポートサービス

GPU メモリとのシームレスな統合
ファイソンaiDAPTIVCache とミドルウェアは GPU メモリを拡張でき、PC には320 GBの追加メモリ、ワークステーションとサーバーには最大 8 TB の追加メモリを提供し、低遅延の LLM トレーニングをサポートします。さらに、業界をリードする100 DWPD という極めて高い耐久性を備え、特別な設計でファイソンの高度なNANDエラー訂正アルゴリズム技術をサポートしています。
シームレスで完璧な統合
- GPUメモリ容量を拡張するために最適化されたミドルウェア
- 2x 2TB aiDAPTIV キャッシュ、70B モデルをサポート
- 低遅延
高耐久性
- 業界をリードするDWPD
5 年以内に 1 日あたり 100 回の書き込み - 高度な NAND 修正アルゴリズムを備えた SLC NAND
推論の向上
aiDAPTIV+ は、最初のトークンリコール時間を短縮することで、推論体験を向上させます。さらに、トークン長を拡張することで、より長く正確な回答を提供するためのコンテキストが増加します。
モデルの無限の可能性を解き放つ

aiDAPTIV+ はフラッシュ メモリと DRAM を統合することでより大きなメモリ リソースを提供するため、モデルサイズは GPU グラフィックス カードの HBM やGDDR メモリの容量によって制限されなくなります。
これにより、大規模なモデルをトレーニングし、かつては大企業やクラウド サービス プロバイダーのみが利用できたコンピューティング需要をより手頃な価格で実行できるようになります。
リソース
aiDAPTIV+の開発プロセス

Computex 2024 での aiDAPTIV+ 基調講演

aiDAPTIV+の概要

aiDAPTIV+の仕組み

サポートするプラットフォーム










業界からの支持
ニュース
 Phison’s aiDAPTIV+ AI solution leverages SSDs to
Phison’s aiDAPTIV+ AI solution leverages SSDs to
expand GPU memory for LLM training ADLINK Launches the DLAP Supreme Series
ADLINK Launches the DLAP Supreme Series Phison Wins Prestigious Best of Show Award at FMS:
Phison Wins Prestigious Best of Show Award at FMS:
the Future of Memory and Storage Phison's new software uses SSDs and DRAM to boost effective memory for AI training —
Phison's new software uses SSDs and DRAM to boost effective memory for AI training —
demos a single workstation running a massive 70 billion parameter model at GTC 2024 Phison's groundbreaking aiDAPTIV+ makes training
Phison's groundbreaking aiDAPTIV+ makes training
AI easier by combining GPUs and SSDs Nvidia GTC:
Nvidia GTC:
Phison Strategic Partnerships Deploying aiDAPTIV+
