Offloads expensive HBM and GDDR memory to cost-effective flash memory. Eliminates the need for large numbers of high-cost and power-hungry GPU cards.
Keeps large data sets local and avoids the cost of transferring data to be processed elsewhere
Offloads expensive HBM and GDDR memory to cost-effective flash memory. Eliminates the need for large numbers of high-cost and power-hungry GPU cards.
Keeps large data sets local and avoids the cost of transferring data to be processed elsewhere
Ease of Use
Easily deploys in your home, office, classroom or data center with a small footprint while using commonplace power & cooling.
Offers command line access or intuitive GUI with all-in-one toolset for model ingest, fine-tuning, and validation and inference.
Easily deploys in your home, office, classroom or data center with a small footprint while using commonplace power & cooling.
Offers command line access or intuitive GUI with all-in-one toolset for model ingest, fine-tuning, and validation and inference.
Control
Enables LLM training behind your firewall. Give you full control over your private data and peace of mind with data sovereignty compliance.
Teach Yourself LLM Fine-Tuning with an AI Training PC
Provides a cost-effective AI Training PC for individuals and organizations to learn how to fine-tune LLMs beyond just simple inference. Fills shortage of skilled talent to train LLMs locally with your own data.
Ultimate turnkey solution to easily train large data models without additional staff and infrastructure. Enables you to scale-up or scale-out nodes linearly to increase training data size and reduce training time.
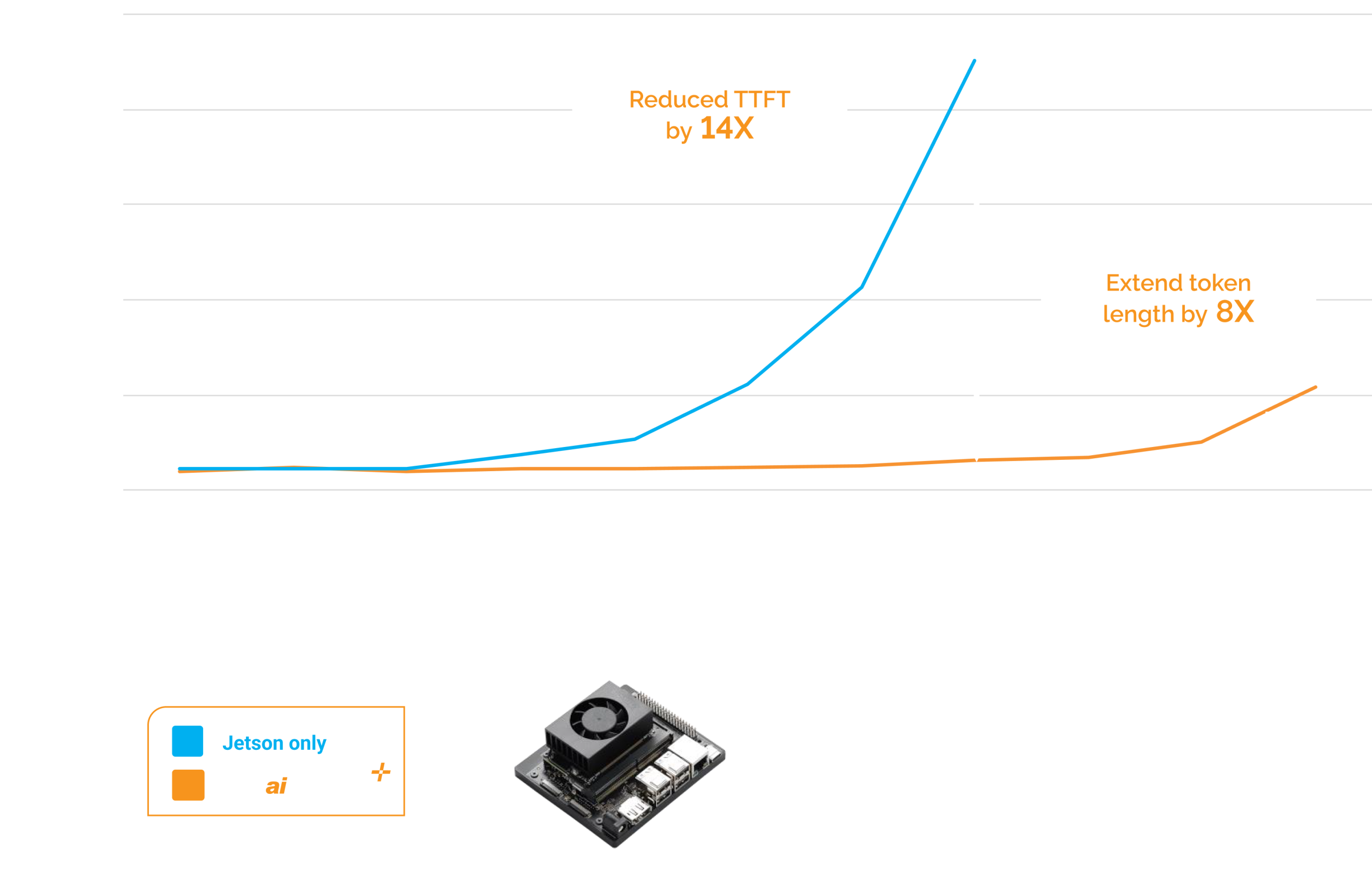
NVIDIA Jetson IoT devices running Phison aiDAPTIV+ accelerate time to first token recall for faster inferencing performance. Also, by extending the token length context is enhanced for longer, more precise answers. Furthermore, aiDAPTIV+ enables LLM model training on Jetson IoT devices.
With an AI Notebook PC powered by a GPU and Phison aiDAPTIV+ individuals can learn how to train LLMs in their own home, office or classroom. In addition, they can operate trained LLMs on-premises and benefit from a model augmented with their data delivering more tailored responses to inference prompts. Using aiDAPTIV+ also improves prompt recall time and gives room for more context which produce lengthier, more precise answers.
LLM training on-premises enables organizations and individuals to enhance general knowledge models with domain-specific data. This provides better usability, relevance and accuracy for a wide range of specialized fields such as medical diagnostics, financial forecasting, legal analysis and product development.
Use a Command Line or leverage the intuitive All-in-One aiDAPTIVPro Suite to perform LLM Training
Supported Models
Llama, Llama-2, Llama-3, CodeLlama
Vicuna, Falcon, Whisper, Clip Large
Metaformer, Resnet, Deit base, Mistral, TAIDE
And many more being continually added
and/or
Built-in Memory Management Solution
Experience seamless PyTorch compliance that eliminates the need to modify your AI application. You can effortlessly add nodes as needed. System vendors have access to AI100E SSD, middleware library licenses, and full Phison support to facilitate smooth system integration.
The optimized middleware extends GPU memory by an additional 320GB (for PCs) up to 8TB (for workstations and servers) using aiDAPTIVCache. This added memory is used to support LLM training with low latency. Furthermore, the high endurance feature offers an industry-leading 100 DWPD, utilizing a specialized SSD design with an advanced NAND correction algorithm.
Optimized middleware to extends GPU memory capacity
2x 2TB aiDAPTIVCache to support 70B model
Low latency
HIGH ENDURANCE
Industry-leading 100 DWPD with 5-year warranty
SLC NAND with advanced NAND correction algorithm
Improves Inference
aiDAPTIV+ enhances the inferencing experience by accelerating Time To First Token recall for faster responses. Furthermore, it extends the token length which provides greater context for lengthier and more accurate answers.
Unlocks Training of Larger Model Sizes
No longer limit your model size fine-tuning due to the HBM or GDDR memory capacity on your GPU card. aiDAPTIV+ expands the memory footprint by intelligently incorporating flash memory and DRAM into a larger memory pool.
This enables larger training models, giving you the opportunity affordably run workloads previously reserved for the largest corporations and cloud service providers.
“Our collaboration with Phison is poised to lower barriers to entry in the AI sector, fostering greater accessibility to local AI computing and training.”
“To deliver maximum value to our clients, ASUS has integrated Phison’s aiDAPTIV+ into our data center solution, offering substantial performance enhancements without increased costs”
“In addition to the PC market, GIGABYTE has also been deeply involved in AI servers for many years. Phison’s innovative AI technology solution, aiDAPTIV+, assists GIGABYTE’s AI server customers by providing another computing architecture for AI model fine-tuning. By integrating SSDs into the AI computing architecture and using SSDs to extend GPU memory, it significantly reduces the cost of AI computations, which is great news for global customers who want to introduce AI-assisted applications.”
"MAINGEAR’s Pro AI Series workstations, driven by Phison aiDAPTIV+, empower users with large language model AI training prowess without excessive costs. Our dedication to crafting highly capable yet budget-friendly solutions guarantee SMBs, universities, and research facilities a competitive advantage in an industry formerly restricted by multimillion-dollar investments."
“Phison’s aiDAPTIV+ enhances our platform with unparalleled edge computing power and creates new prospects for our users and developers.”
Phison’s dedicated technical support offers end-to-end assistance for aiDAPTIV+ throughout the entire product lifecycle, from initial implementation to on-going operation and optimization. Our team of experts provides rapid troubleshooting, firmware adjustments, and performance tuning to ensure seamless integration and maximum product efficiency. With access to our support engineers and cutting-edge tools, Phison’s aiDAPTIV+ customers and partners can accelerate time-to-market while maximizing return on investment for their AI workloads.
Phison’s dedicated technical support offers end-to-end assistance for aiDAPTIV+ throughout the entire product lifecycle, from initial implementation to on-going operation and optimization.
Our team of experts provides rapid troubleshooting, firmware adjustments, and performance tuning to ensure seamless integration and maximum product efficiency.
With access to our support engineers and cutting-edge tools, Phison’s aiDAPTIV+ customers and partners can accelerate time-to-market while maximizing return on investment for their AI workloads.