
Select your language
Affordable On-Site LLM Training
and Enhanced Inferencing
Download Solution Brief




Fits Your
Budget

Simple to Use
and Deploy

Keeps Data in
Your Control

Note: Assumes 4 NVIDIA 6000 ADA GPUs on-site versus 8 NVIDIA H100 GPUs in the cloud
Affordable
Offloads expensive HBM and GDDR memory to cost-effective flash memory. Eliminates the need for large numbers of high-cost and power-hungry GPU cards.

Ease of Use
Easily deploys in your home, office, classroom or data center with a small footprint while using commonplace power & cooling.
Offers command line access or intuitive GUI with all-in-one toolset for model ingest, fine-tuning, and validation and inference.

Control
Enables LLM training behind your firewall. Give you full control over your private data and peace of mind with data sovereignty compliance.

Teach Yourself LLM Training
with an AI Training PC
Provides a cost-effective AI Training PC for individuals and organizations to learn how to fine-tune LLMs beyond just simple inference. Fills shortage of skilled talent to train LLMs locally with your own data.


Scale Up or Scale Out
Ultimate turnkey solution to easily train large data models without additional staff and infrastructure. Enables you to scale-up or scale-out nodes linearly to increase training data size and reduce training time.

IoT for Edge
Computing and Robotics
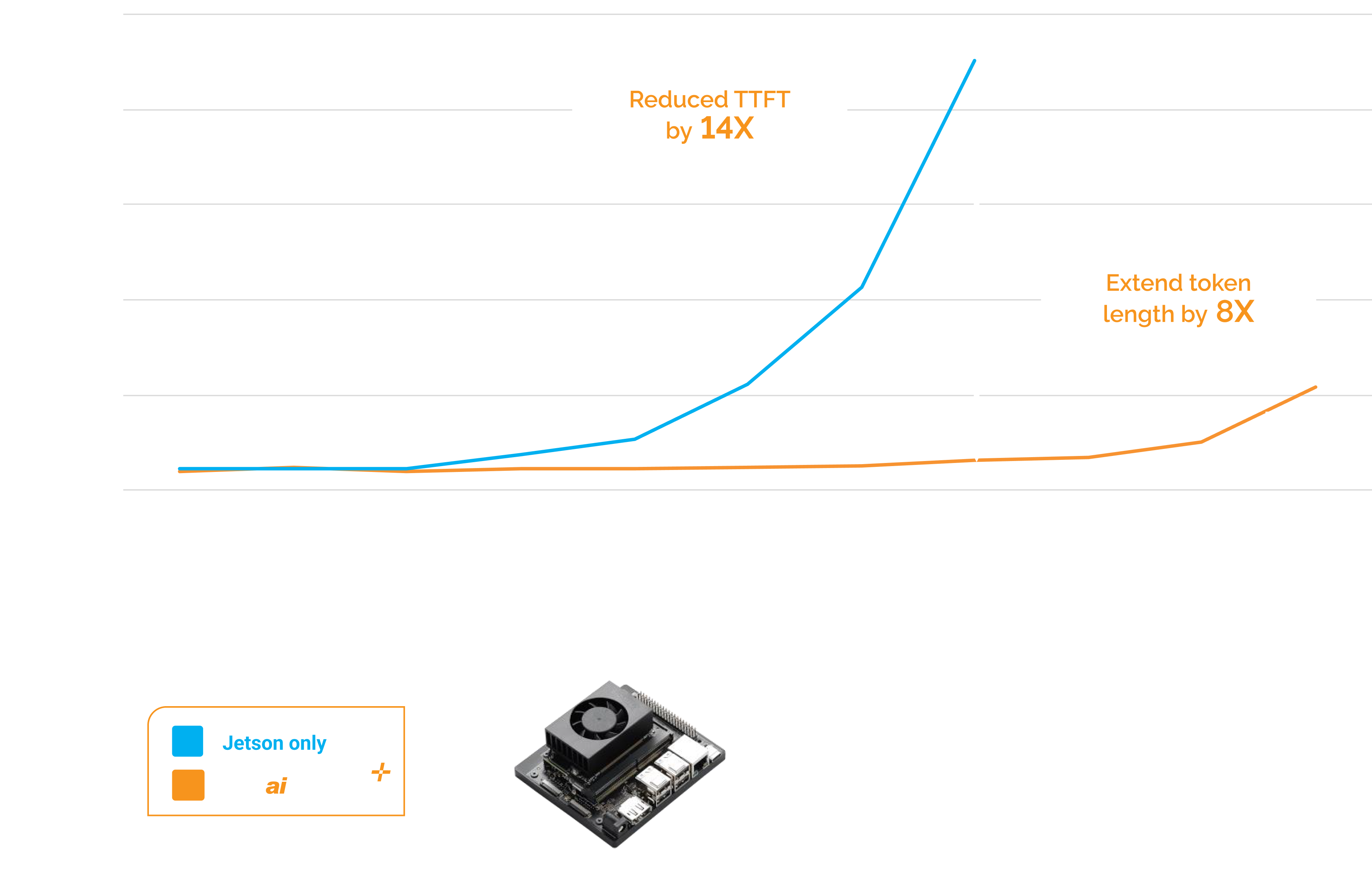
NVIDIA Jetson IOT devices running Phison aiDAPTIV+ accelerate time to first token recall for faster inferencing performance. Also,
by extending the token length context is enhanced for longer, more precise answers.
Furthermore, aiDAPTIV+ enables LLM model training on Jetson IoT devices.

AI Notebook PC
With an AI Notebook PC powered by a GPU and Phison aiDAPTIV+ individuals can learn how to train LLMs in their own home, office or classroom. In addition, they can operate trained LLMs on-premises and benefit from a model augmented with their data delivering more tailored responses to inference prompts. Using aiDAPTIV+ also improves prompt recall time and gives room for more context which produce lengthier, more precise answers.

LLM Training Use Cases
LLM training on-premises enables organizations and individuals to enhance general knowledge models with domain-specific data. This provides better usability, relevance and accuracy for a wide range of specialized fields such as medical diagnostic, financial forecasting, legal analysis and product development.
Phison aiDAPTIV+
LLM Training Integrated Solution
Use a Command Line or leverage the intuitive All-in-One aiDAPTIVPro Suite to perform LLM Training

Supported Models
- Llama, Llama-2, Llama-3, CodeLlama
- Vicuna, Falcon, Whisper, Clip Large
- Metaformer, Resnet, Deit base, Mistral, TAIDE
- And many more being continually added


Built-in Memory Management Solution
Experience seamless PyTorch compliance that eliminates the need to modify your AI application. You can effortlessly add nodes as needed. System vendors have access to AI100E SSD, middleware library licenses, and full Phison support to facilitate smooth system integration.
aiDAPTIV+ BENEFITS
- Transparent drop-in
- No need to change your AI Application
- Reuse existing HW or add nodes
aiDAPTIV+ MIDDLEWARE
- Slice model, assign to each GPU
- Hold pending slices on aiDAPTIVCache
- Swap pending slices w/ finished slices on GPU
FOR SYSTEM INTEGRATORS
- Access to ai100E SSD
- Middleware library license
- Full Phison support to bring up

Seamless Integration with GPU Memory
The optimized middleware extends GPU memory by an additional 320GB (for PCs) up to 8TB (for workstations and servers) using aiDAPTIVCache. This added memory is used to support LLM training with low latency. Furthermore, the high endurance feature offers an industry-leading 100 DWPD, utilizing a specialized SSD design with an advanced NAND correction algorithm.
SEAMLESS INTEGRATION
- Optimized middleware to extends GPU memory capacity
- 2x 2TB aiDAPTIVCache to support 70B model
- Low latency
HIGH ENDURANCE
- Industry-leading 100 DWPD with 5-year warranty
- SLC NAND with advanced NAND correction algorithm
Improves Inference
aiDAPTIV+ enhances the inferencing experience by accelerating Time To First Token recall for faster responses. Furthermore, it extends the token length which provides greater context for lengthier and more accurate answers.
Unlocks Training of Larger Model Sizes

No longer limit your model size fine-tuning due to the HBM or GDDR memory capacity on your GPU card. aiDAPTIV+ expands the memory footprint by intelligently incorporating flash memory and DRAM into a larger memory pool.
This enables larger training models, giving you the opportunity affordably run workloads previously reserved for the largest corporations and cloud service providers.
Resources
How aiDAPTIV+ Was Created

aiDAPTIV+ Keynote at Computex 2024

Overview of aiDAPTIV+

How aiDAPTIV+ Works

Supporting Platforms










Industry Support
In the News
 Phison’s aiDAPTIV+ AI solution leverages SSDs to
Phison’s aiDAPTIV+ AI solution leverages SSDs to
expand GPU memory for LLM training ADLINK Launches the DLAP Supreme Series
ADLINK Launches the DLAP Supreme Series Phison Wins Prestigious Best of Show Award at FMS:
Phison Wins Prestigious Best of Show Award at FMS:
the Future of Memory and Storage Phison's new software uses SSDs and DRAM to boost effective memory for AI training —
Phison's new software uses SSDs and DRAM to boost effective memory for AI training —
demos a single workstation running a massive 70 billion parameter model at GTC 2024 Phison's groundbreaking aiDAPTIV+ makes training
Phison's groundbreaking aiDAPTIV+ makes training
AI easier by combining GPUs and SSDs Nvidia GTC:
Nvidia GTC:
Phison Strategic Partnerships Deploying aiDAPTIV+
Technical Support
Phison’s dedicated technical support offers end-to-end assistance for aiDAPTIV+ throughout the entire product lifecycle, from initial implementation to on-going operation and optimization. Our team of experts provides rapid troubleshooting, firmware adjustments, and performance tuning to ensure seamless integration and maximum product efficiency. With access to our support engineers and cutting-edge tools, Phison’s aiDAPTIV+ customers and partners can accelerate time-to-market while maximizing return on investment for their AI workloads.
